
talat
Realtime meeting notes that don’t leave your Mac
talat Wants to Be Your Meeting Brain, and It Refuses to Phone Home
The Macro: The Privacy Angle Nobody Wants to Admit Is the Real Problem
Here’s the thing nobody says out loud about Otter, Fireflies, and most of the cloud-transcription crowd: when you record a sales call or a board meeting through their apps, that audio goes somewhere. Usually to a server you don’t control, processed by models you didn’t choose, under terms of service that most people never read (there’s a whole product built around that problem, actually). That’s a reasonable tradeoff for a lot of users. It’s not a reasonable tradeoff for lawyers, therapists, founders talking about unannounced fundraises, or basically anyone in a regulated industry.
The AI meeting notes category has gotten genuinely crowded. Granola raised money and built a following. Otter has been around long enough that people forget it’s still growing. Notion and other all-in-ones have bolted on recording features. The pitch is always some version of: never take notes again, get a summary, search your history.
But here’s what I think is actually happening: the entire category has been optimized for convenience at the exact moment when regulatory scrutiny and data breach fatigue should have flipped the equation. We’re in a weird moment where everyone assumes cloud processing is inevitable, when actually it’s just the default because nobody challenged it. Most of these tools treat on-device processing as a marketing footnote if they mention it at all. The assumption is that users will accept cloud processing because the convenience wins. For casual use, maybe it does. But there’s a real segment of professionals who would use AI meeting notes if they trusted where the data went, and that segment has been mostly ignored because it’s harder to monetize.
That’s the gap talat is pointing at. It’s not a new product category. It’s a deliberate constraint applied to an existing one, and constraints are actually how you build defensible products.
The Micro: A Mac App That Actually Stays on Your Mac
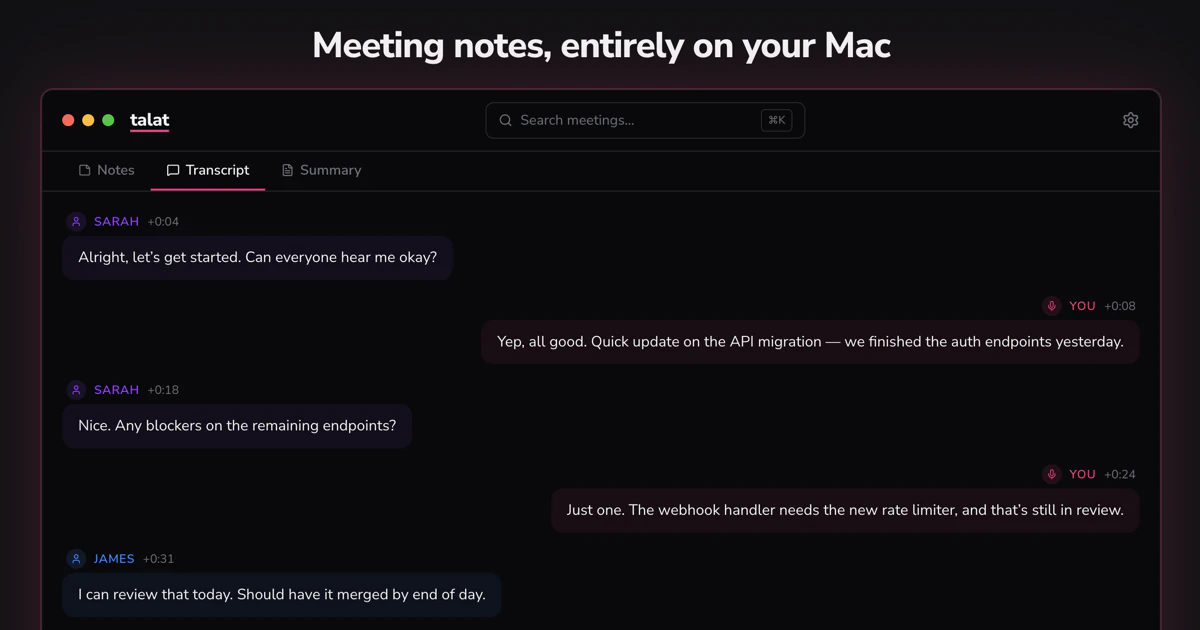
talat is a macOS app. That’s the whole ballgame architecturally. It runs on Apple Silicon and uses the Neural Engine for transcription and summarization, which means the compute happens locally and the audio never touches a remote server. The download is 20MB. It’s a one-time purchase with all future updates included, which is a pricing model that feels almost retro at this point and will probably be the detail that gets shared most in developer forums.
The core flow is simple. You join a meeting in Zoom, Teams, Google Meet, or whatever you already use. talat detects that a conferencing app has grabbed your microphone and starts recording quietly. You get a notification. That’s it. It captures both your mic and system audio, so it transcribes everyone, and it attempts speaker diarization, meaning it tries to label who said what. You can edit speaker assignments in real time, which is a small thing that matters a lot if you’ve ever cleaned up a transcript where the AI decided two people were the same person.
When the meeting ends, a local LLM generates a summary: key points, decisions, action items. Everything is searchable, stored locally, and exportable.
The power-user features are where it gets interesting. You can bring your own LLM provider, write custom summarization prompts, auto-export to Obsidian, push data out via webhooks, or query your meeting history through an MCP server. That last one is notable. MCP (Model Context Protocol) integration means you can wire talat’s notes into other AI tools as a structured data source, which turns it from a notes app into something closer to a local knowledge layer.
It got solid traction on launch day, which suggests the privacy angle resonates more than the incumbents are giving it credit for.
The team is also explicit that it runs alongside Granola or Otter. No forced switching. That’s a smart zero-friction onboarding move.
The Verdict: This Works, But Only If They Stay Boring
I think talat is going to win with a specific but meaningful slice of the market, and the one-time pricing model is actually the right choice even if it looks wrong on a VC pitch deck. Here’s why: enterprise compliance teams and regulated professionals will pay once and keep paying in renewals because they trust the model. Cloud-transcription companies train on call data as a feature, not a bug. That’s become their business model, and it corrupts their incentives. talat’s constraint forces them to stay honest.
The thing that determines whether this company exists in two years is this: can the on-device transcription actually handle accented speech and cross-talk without degrading past the point of usefulness? That’s where cloud models with massive training sets usually win, and if talat’s local models fail here, the product becomes a niche toy for English speakers in quiet rooms. That’s not a real business.
If they nail transcription accuracy, the Obsidian and webhook integrations become genuine distribution channels into the developer-tools world, which is exactly where you want to be. The MCP integration could actually break through in a way that reaches non-technical buyers through developer evangelism.
The real risk most people are missing: privacy as a primary value proposition works for early adopters, but the market has to shift before it scales. That shift is actually happening now with SOC 2 audits and compliance budgets, not because users suddenly care about privacy, but because their companies legally have to. talat is timing this right.
Prediction: 18 months from now, talat has between 2000 and 5000 paying customers, most of them in legal, finance, or healthcare. They’re profitable or close to it. And they’re still boring, which means they’re winning.