
auto-mode-by-claude-code
Let Claude make permission decisions on your behalf
Anthropic Wants Claude to Stop Asking for Permission
The Macro: Why the Developer Tools Market Is Solving the Wrong Problem First
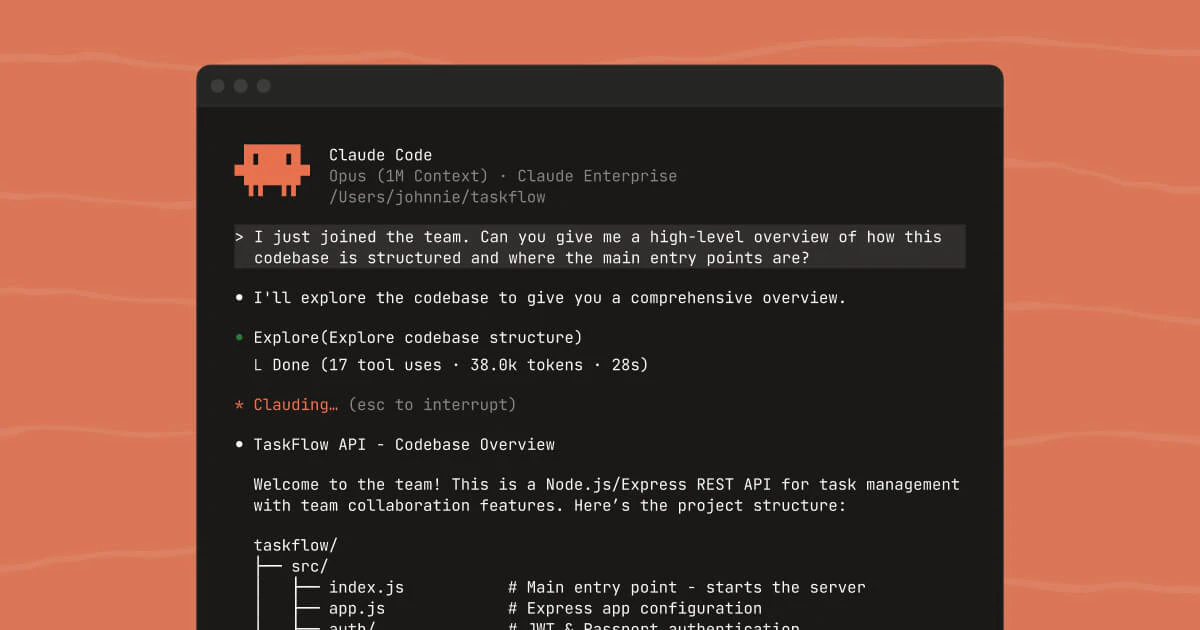
The core tension in AI-assisted coding has been sitting in plain sight for two years. Models got smarter. Context windows got bigger. And developers still had to sit there, clicking approve on every file write like they were manually installing a printer driver in 2009.
This is not a small friction. When you’re running a long agentic task, every permission prompt is a context switch. It breaks flow, and for developers using AI agents to work through complex multi-step problems, that interruption cost compounds fast. The whole promise of autonomous coding assistants starts to hollow out if a human has to stay tethered to the keyboard the whole time.
The market around developer productivity tooling is large and getting larger. According to multiple market research sources, the productivity software sector is projected to grow from around $62.5 billion in 2024 toward well over $140 billion by the early 2030s. But I think most of this market is chasing the wrong metric. Everyone’s obsessed with speed and autonomy, when what actually matters is whether developers trust the thing they’re giving control to. That’s harder to measure, harder to demo in a pitch meeting, and way harder to solve. Most of the crowded corner - Cursor, Zed, Kilo Code, GitHub Copilot - keeps iterating on the same binary choice: either you approve everything manually, which is safe but tedious, or you disable permissions entirely, which is fast but reckless. That binary is the actual problem. It’s blunt architecture for a nuanced situation, and frankly, I think the entire sector has been too comfortable living with it.
The Micro: A Classifier in the Middle Seat
Auto mode for Claude Code does something structurally interesting. It doesn’t just say yes to everything or no to everything. It puts a classifier in between.
When Claude attempts an action, whether that’s writing to a file or running a bash command, the classifier evaluates it. If the action reads as low-risk, it runs automatically. If it reads as risky, it gets blocked and routed differently. The result is a tiered permission system that tries to match the human oversight to the actual risk of the action, rather than applying the same friction to everything equally.
According to Anthropic’s own description, the recommendation is to use this in isolated environments. That caveat is doing real work. Auto mode isn’t a feature for casually pointed at your production codebase. It’s designed for sandboxed setups where a bad call has bounded consequences.
This is a thoughtful design constraint, and also an honest one. Anthropic isn’t pretending the classifier is infallible. They’re saying: here is a tool that makes autonomous operation more practical, and here is the context where it makes sense to use it.
The feature got solid traction on launch day, which tracks with how much frustration has built up around the approval loop problem.
For people who’ve watched other attempts at autonomous agent workflows promise full autonomy and then quietly add a dozen confirmation steps back in, this approach is more honest about its limits. The middle path, not full autonomy, not full manual control, is less marketable as a headline but more useful in practice.
The details I’d want to see spelled out are the classifier’s error modes. Specifically: how often does it flag safe actions as risky, and how often does it let genuinely risky ones through? Those two failure rates have very different consequences, and right now there’s no public data on either.
The Verdict: This Works, But Only If Anthropic Doesn’t Flinch
Auto mode is a real product solving a real problem, and I think it’s going to work. The interruption tax on agentic coding is not imagined, and a classifier-based middle tier is genuinely smarter than the binary everyone else has settled for. Anthropic is thinking about the right layer here.
But here’s the thing: developer trust in automation is fragile, and one visible failure will do more damage than a thousand quiet successes. The moment a classifier waves through something it shouldn’t - even once - that failure will circulate on social and stick. The false-negative rate on risky actions needs to be nearly flawless, or this entire bet collapses.
The one thing that determines if this company exists in two years is whether they can maintain that trust through their first major incident. And they will have one. Every automation system does. The question is whether they respond by tightening the classifier (good) or loosening it to chase adoption numbers (death).
At 60 days, watch adoption patterns. If this is mostly being used in CI pipelines and isolated dev containers, Anthropic has built something enduring. If developers start using it against live repositories because the friction of proper isolation feels like too much work, the design failed to prevent what it knew would happen.
My prediction: This feature hits 15-20% adoption among serious Claude users within six months, then plateaus hard when someone’s classifier mistake gets posted on Twitter. The question isn’t whether auto mode works - it does. The question is whether Anthropic has the discipline to keep it conservative enough to stay trusted.